Proposal
Summary
We are going to implement a distributed, parallel LDA (latent dirichlet allocation) algorithm for building topic model on large corpus using the OpenMPI library and CUDA parallel programming model. We will parallelize the original sequential algorithm over a cluster of GPUs.
Background
In natural language processing, Latent Dirichlet Allocation (LDA) is a generative statistical model that allows sets of observations to be explained by unobserved groups that explain why some parts of the data are similar. Essentially, LDA is a generative directed graphical model for topic discovery where each document may be viewed as a mixture of various topics generated by Dirichlet prior. Besides, the likelihood of occurrence of words in each document can be well represented by a multinomial distribution. Learning the various distributions is a problem of Bayesian inference, which can be solved Markov chain Monte Carlo algorithm. In LDA, we choose to use collapsed Gibbs sampling because we have conjugate prior in compound distribution.
Generative process
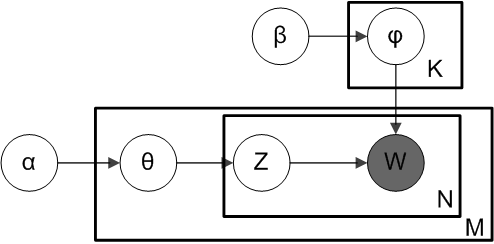
Documents are represented as random mixtures over latent topics, where each topic is characterized by a distribution over words. LDA assumes the following generative process for a corpus D consisting of M documents each of length Ni.
- Choose a multinomial topic distribution θ for the document (according to a Dirichlet distribution Dir(α) over a fixed set of K topics)
- Choose a multinomial term distribution φ for the topic (according to a Dirichlet distribution Dir(β) over a fixed set of N terms)
- For each word position
- choose a topic Z according to multinomial topic distribution θ.
- choose a word W according to multinomial term distribution φ.
Implementation process
Given a set of documents and a fixed topic number K, we want to use LDA to learn the topic representation of each document and the words associated to each topic.
- Initialize topic distribution as uniform. Randomly assign each word in documents to one of the K topics.
- Calculate global distributions for topic-term and doc-topic.
- Iterate until convergence
- For each document and each word
- Compute p(topic t | document d, word w) = C * p(topic t | document d) * p(word w | topic t) according to global distributions for each topic.
- Randomly assign one topic to current word according to above distribution.
- Update global distributions.
- For each document and each word
Challenge
The original algorithm is totally sequential. There are mainly three parts taking up the most computation time so they are what we need to parallelize.
- Gibbs sampling is by definition sequential. Every choice of topic depends on all the other topics. We need to modify the algorithm and try approximate distributed LDA.
- Multinomial topic distribution generation in each sampling involves many independent computation steps as well as probability normalization. We need to fully parallelize this part.
- Faster sampling is the operation of assigning each word a topic. This operation will be called in a very high frequency. Though this operation will not be parallelized, we still need to find faster implementation.
The basic idea is to split the gibbs sampling into different machines and each machine updates their generative distribution models locally. Each machine will treat their local distribution as global distribution, and communicate to exchange their updates for every one or several iterations. This method has these challenges:
- How to split the gibbs sampling.
- Choose which synchronization model.
- How to parallelize Multinomial topic distribution generation given big topic number K and large corpus by GPUs in single node.
- How to minimize the communication overheads between
- Different machines
- CPU and GPU
Resources
We plan to use latedays cluster for testing our system. The latedays cluster supports OpenMPI and CUDA which meets our requirements. The possible problem is that there maybe many other users using this cluster and have influence on our performance.
Goals and Delieverables
Plan to achieve:
- An OpenMPI and CUDA based, distributed and parallel LDA implementation.
- Implement banchmark based on Standford NLP toolkits.
- Conduct experiments on NYTimes dataset.
- Achieve high performance over banchmark results.
Hope to achieve:
- Compare our system with state-of-art parallel LDA systems like Yahoo LDA, lightlda, etc. and achieve similar results.
Platform choice
As mentioned before, we plan to use latedays clusters.
Schedule
| Dates | Planned Goals |
|---|---|
| 4/10-4/16 | Prepare dataset; Build banchmark system; Read related papers and make system design |
| 4/17-4/23 | Implement distrubted version; Prepare for checkpoint report |
| 4/24-4/30 | Implement parallelism on each machine; Implement faster sampling |
| 5/1-5/8 | Optimize the results and conduct experiments |
| 5/9-5/12 | Prepare for final report |
References
[1] Blei, David M., Andrew Y. Ng, and Michael I. Jordan. “Latent dirichlet allocation.” Journal of machine Learning research 3.Jan (2003): 993-1022.
[2] Newman, David, et al. “Distributed algorithms for topic models.” Journal of Machine Learning Research 10.Aug (2009): 1801-1828.
[3] Yao, Limin, David Mimno, and Andrew McCallum. “Efficient methods for topic model inference on streaming document collections.” Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2009.
[4] Li, Aaron Q., et al. “Reducing the sampling complexity of topic models.” Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2014.
[5] Yu, Hsiang-Fu, et al. “A scalable asynchronous distributed algorithm for topic modeling.” Proceedings of the 24th International Conference on World Wide Web. ACM, 2015.
[6] Yuan, Jinhui, et al. “Lightlda: Big topic models on modest computer clusters.” Proceedings of the 24th International Conference on World Wide Web. ACM, 2015.